HTML Scraping or Surviving Orrible Corporate Tools
At work I have to fill my weekly timesheet. We use Planisware’s Timecard to record time spent on the various projects we are assigned to work on.
So you need to known what the total working time is for the day. For that our badging in and out is recorded and passed to Chronogestor which does sums them up and provides both a sexagesimal and decimal format.
When there is an anomaly the sums are blocked till the request you submitted to fix it is implemented… So I thought I could do some web scraping and extract my clockings from the relevant CG’s page, make the total for the day (in decimal form: in Timecard we record time in decimal form, i.e. 3.5 is 3 hours and 30 minutes.) and fill Timecard.
HTML Scraping to the rescue
Let’s take the page for the weekly clockings (in case of anomalies the rows like “Temps pointe” / “Temps valide” are empty):
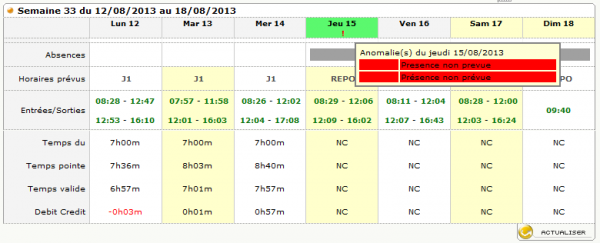
I initially tried with some Python examples using lxml but got stuck. CG complaines if you are using Google Chrome (and the tools above use Webkit, the web browser engine, behind the scene).
Also I soon realized CG does a lot of rendering via Javascript while I initially assumed it would have been a simple HTML page with a static table for the clockings. (This would have been to simple to implement! What a mess!)
I decided to go for SlimerJS the scriptable browser that runs on top of Gecko, the web engine of Mozilla Firefox. (PhantomJS is the equivalent for Blink/WebKit used in Google Chrome.)
Nothing strange about using Javascript of course but CG sucks at it: it is a last millenium tool which has been hastily brought to this century without any knowledge of the web technologies (and any taste for usability and beauty.) Just check the generated DOM elements and you will see that the uniqueness (within a page) of id is not at all respected.
From the page for the weekly clockings shown above, using Firefox Developer Tools you can see that the table for the clockings (“Entrées/Sorties” row) can be selected via the following CSS path (line 58):
cg.js
var page = require("webpage").create();
var moment = require("moment.min");
var system = require("system");
// retrieve proxy user and password from command line options
// (!! I havent found any easier way to do it: no slimerjs API for it !!)
// use Array.findIndex in ECMAScript 6
// see https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/findIndex
var proxyauth = (system.env["__SLIMER_ARGS"]).split(" ");
var idx = proxyauth.findIndex(function(elem, i, array) {
return elem.match(/auth/);});
// use Destructuring assignment in ECMAScript 6
// see https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Destructuring_assignment
var [puser, ppwd] = (proxyauth[++idx]).split(":");
// extract the in/out badge clockings
// return an array like
// a["1"] = ["08:53", "12:13"] // 1 is Monday
// ...
// a["7"] = ["08:53", "12:13"] // 7 is Sunday
var extractClockings = function(selector) {
var elems = $(selector);
var week = [];
// iterate thru the "Clockings" table
$(elems).each(function(index){ // index starts from 1
var tmp = [];
// collect the readings for this one day
var clocks = $(this).find("a");
if (clocks.length) {
var c;
for (var i = 0; i < clocks.length; i++) {
tmp.push($(clocks[i]).text());
}
}
week[index-1] = tmp;
console.log(week[index]);
});
return week;
};
// could use Template string,
// see https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/template_strings
// but Firefox supports it as of ver 34 (at Eurocontrol we are at 28)
var data = 'LOGIN=' + puser + '&PASSWORD=' + ppwd;
// pass (it is arg[0]) any day in the week you want to have the clockings
// and here we find the relevant Monday
var ref_date = moment(phantom.args[0], "DD/MM/GGGG").isoWeekday(1);
// ChronoGestor URLs
var url = "http://flexitime.eurocontrol.int:81/modintrachronotique/login";
var clock = "http://flexitime.eurocontrol.int:81/modintrachronotique/planning/pointages?&jour_sel=" + ref_date.format("DD/MM/YYYY");
// selector for clockings (sub)table [use Firefox Devtools to find it!]
var sel = "#divText > table:nth-child(2) > tbody:nth-child(1) > tr:nth-child(6) > td:nth-child(1) > table:nth-child(1) > tbody:nth-child(1) > tr:nth-child(1) td";
// STEP 1: login
page.open(url, 'post', data, function(status){
if (status == "success") {
var npage = require("webpage").create();
// in order to eventually be able to console.log inside the call to evaluate...
npage.onConsoleMessage = function (msg) {
console.log(msg);
};
// STEP 2: navigate to "Daily Movements" page, i.e. 'clock' URL
npage.open(clock, function(status) {
if (status == "success") {
// include JQuery for easy selection of the 'Clockings' (sub)table via CSS
npage.includeJs("http://cdnjs.cloudflare.com/ajax/libs/jquery/2.0.3/jquery.min.js", function() {
var week = npage.evaluate(extractClockings, sel);
// for each day
for (var d = 0; d < week.length; d++) {
// calculate the worked minutes
var clock_in, clock_out,
minutes = 0, decimal_hour, decimal_minutes,
sum_minutes = 0, sum_decimal_minutes, sum_decimal_hours;
console.log("");
// take couples or readings
for (var c = 0; c < ~~(week[d].length/2); c++) {
// read in and out
clock_in = moment(week[d][2*c],"HH:mm");
clock_out = moment(week[d][2*c+1],"HH:mm");
// minutes between out and in
minutes = clock_out.diff(clock_in) / 60000;
sum_minutes += minutes; // cumulative minutes for the relevant day
// decimal format transformations
decimal_hour = Math.floor(minutes / 60);
decimal_minutes = (minutes % 60) * 5 / 3;
decimal_hour = Math.floor10(decimal_hour + (decimal_minutes/100), -2);
console.log(ref_date.format("dddd") + " -> hours worked (decimal): " + decimal_hour + " (" + minutes + " min)");
}
console.log("--------------------------------------");
sum_decimal_hour = Math.floor(sum_minutes / 60);
sum_decimal_minutes = (sum_minutes % 60) * 5 / 3;
sum_decimal_hour = Math.floor10(sum_decimal_hour + (sum_decimal_minutes/100), -2);
console.log(ref_date.format("dddd DD/MM/YYYY") + " -> total hours worked (decimal): " + sum_decimal_hour + " (" + sum_minutes + " min)");
console.log("");
ref_date.add(1, 'd');
}
});
}
else {
console.log("The loading of clockings has failed");
}
});
}
else {
console.log("Sorry, the login page is not loaded");
}
slimer.wait(5000);
slimer.exit();
});
// from https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Math/round
(function(){
/**
* Decimal adjustment of a number.
*
* @param {String} type The type of adjustment.
* @param {Number} value The number.
* @param {Integer} exp The exponent (the 10 logarithm of the adjustment base).
* @returns {Number} The adjusted value.
*/
function decimalAdjust(type, value, exp) {
// If the exp is undefined or zero...
if (typeof exp === 'undefined' || +exp === 0) {
return Math[type](value);
}
value = +value;
exp = +exp;
// If the value is not a number or the exp is not an integer...
if (isNaN(value) || !(typeof exp === 'number' && exp % 1 === 0)) {
return NaN;
}
// Shift
value = value.toString().split('e');
value = Math[type](+(value[0] + 'e' + (value[1] ? (+value[1] - exp) : -exp)));
// Shift back
value = value.toString().split('e');
return +(value[0] + 'e' + (value[1] ? (+value[1] + exp) : exp));
}
// Decimal round
if (!Math.round10) {
Math.round10 = function(value, exp) {
return decimalAdjust('round', value, exp);
};
}
// Decimal floor
if (!Math.floor10) {
Math.floor10 = function(value, exp) {
return decimalAdjust('floor', value, exp);
};
}
// Decimal ceil
if (!Math.ceil10) {
Math.ceil10 = function(value, exp) {
return decimalAdjust('ceil', value, exp);
};
}
})();Run it!
The scraping is run as follows:
C:\goodies\cg> cg usr:pwd 03/02/2015Where usr is the userid and pwd is the password for both the internet proxy and ChronoGestor.
cg is a simple (stupid?) .bat script
cg.bat
REM A simple wrapper around slimmerjs
REM proxy server/port are hardcoded no need to bother the user every time
@slimerjs -proxy pac.eurocontrol.int:9512 -proxy-auth %1 cg.js %2Loggin in
The relevant lines from the cg.js script 6-16,47,54,61-63 (see the code above.)
Here we reuse the proxy user and account values which, as per company policy, are the same as our login name and password. And to do that I had to hack an implementation detail whereby slimer.js sets an environment variable __SLIMER_ARGS with the options passed on the command line. (Lines 6-16)
Extract the clockings
In order to extract the right cells for the clocking, I inject JQuery and use webpage.evaluate() function from the API in order to execute extractClockings (sel will be passed as argument to extractClockings, it is the CSS path shown above). Lines 74-76.
extractClockings reads a list of <a> elements for each day. Lines 18-42.
Count the minutes
The rest is a matter of summing up the minutes and printing the values. Lines 78-114.
Code
Code is available in this gist https://gist.github.com/espinielli/aa410dbe7ff9b05b9c8f